This book introduces the annotation approach of the Treebank Semantics Parsed Corpus (TSPC). The TSPC is a corpus of English for general use with hand worked syntactic parse analysis for approaching half-a-million words.
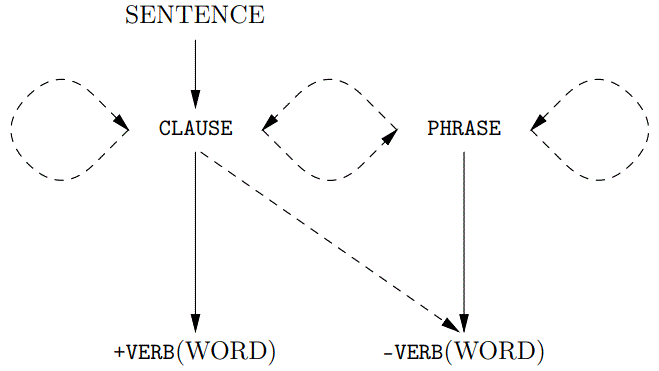
Parse analysis reveals smaller and smaller layers of structure. As a beginning, consider layers introduced by following possible paths through picture (1.1), from the highest sentence layer through to the lowest word layers, via clause and possibly phrase layers, with the arrow X ⟶ Y interpreted: ‘X immediately contains Y’. Dashed arrows indicate optionality.
As an internal layer in the hierarchy, a CLAUSE is reached from the outermost sentence layer, and subsequently a PHRASE can be reached from a clause layer. In addition, clauses can occur within clauses, phrases can occur within phrases and clauses can occur within phrases.
A sentence is at the top of the hierarchy, so it is the largest unit considered. (A discourse grammar would look above the sentence layer.) A word is at the other end of the hierarchy. (It is possible to go inside words to consider morphology, that is, the components from which words are made, which would be lower in the hierarchy of structure.) Chapter 2 will detail the range of possible words, but for considering the hierarchy, it is helpful to start from an outlook where words are of two kinds:
Sentence and word layers are fairly easily identified by conventions of the English writing system. Sentences are delimited by an initial capital letter and a final full-stop (or question-mark or exclamation-mark). Words are created with single character strings that are delimited by a space on each side (or punctuation mark other than a hyphen or apostrophe). But these conventions are not always followed. An important exception is when a sequence of words behaves syntactically in an idiomatic way (e.g. ‘as long as’, ‘with regard to’, ‘by the way’). Such word sequences will be analysed as if single words, with each component separated by underscore characters in a single character string, as in (1.2).
To allow for integration into the parse analysis, punctuation points, quotation marks, and brackets (‘.’ ‘?’ ‘!’ ‘:’ ‘;’ ‘,’ ‘-’ ‘(’ ‘)’ etc.) are treated as words; see section 2.11 for details.
A simple sentence consists of one clause. A clause contains minimally a verb. Following picture (1.1), paths start: SENTENCE,CLAUSE. This initial clause layer is known as the matrix clause and is symbolised most generally with IP-MAT. IP is an abbreviation for Inflectional Phrase, which is another way to say ‘clause’. IP-MAT may be replaced by a more specific name. For example, IP-IMP is used instead of IP-MAT to identify a sentence as an imperative. Consider the imperative sentence (1.3), which is comprised of a single verb contained within a single clause.
This can be given the analysis of (1.4) from sentence layer to words, with the punctuation treated as a word.
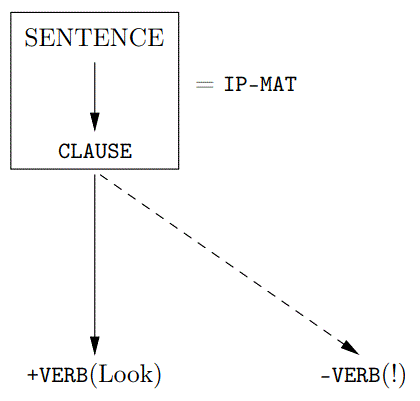
A way to write the parse information pictured in (1.4) from sentence layer to words is with (1.5).
With (1.5), each word of the parse comes at the end of its own line, with each line presenting path information from the root (IP-IMP) layer through to a word layer. The last line is the ID node for the parse.
Consider (1.6) as an example of the interplay between internal clause and phrase layers.
Analysis of (1.6) gives the tree structure of (1.7).
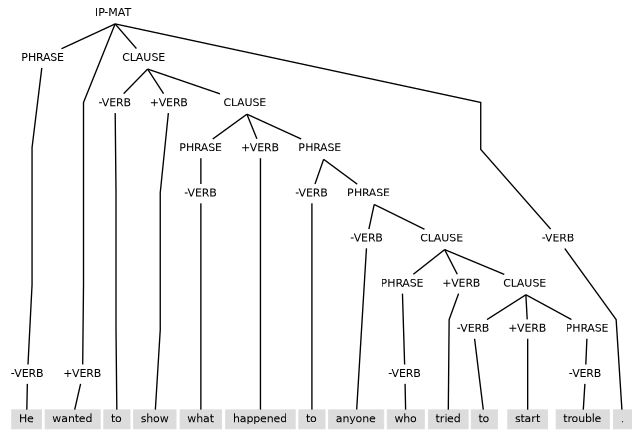
When viewed in terms of paths from sentence layer to words, the analysis of (1.7) becomes (1.8).
Notably, the paths of (1.8) conform to picture (1.1) above. They start with a sentence and clause layer (IP-MAT), and then can have clauses within clauses, phrases within clauses, phrases within phrases, clauses within phrases, verbs with occasional non-verb words within clauses, and non-verb words within phrases.
Each of the units of structure in pictures (1.4) and (1.7) above, and paths of (1.5) and (1.8) above, is either a clause or a phrase. It is typical to refer to such units as constituents.
We have so far categorised words into being either:
Because of this categorisation, we have already been able to distinguish clause constituents from phrase constituents:
We will want to further distinguish phrases into being of various kinds based on the words they contain. To this end, we can divide -VERB words into classes such as:
With such divisions, phrases can be sub-divided into:
Establishing the range of word classes is the aim of chapter 2. Looking at phrase classes in detail is pursued in chapter 3. A big part of chapters 2 and 3 will be to raise and answer questions of form, that is, how words and constituents look — their shape or appearance, and what their internal structure happens to be. But form is not the full story required for parsing: In order to gain motivation for having structure, we will often need to be equally concerned to explore the function that words and constituents perform in the larger structures which contain them.
The dual concern for form and function in chapters 2 and 3 will be carried over to an exploration of clause constituents in chapter 4. Chapter 5 details options available for realising complex sentences with clause-within-clause subordination.
The parsing practise developed over chapters 3, 4, and 5 will involve specifying form and function for the constituents named PHRASE and CLAUSE above.
Chapters 6, 7, and 8 integrate verb codes that signal the clause requirements of verbs.
Chapter 10 extends coverage to constructions with displacements where full analysis can require indexing. Chapter __bindingchap__ discusses exceptional scope, control and anaphora. Chapter 12 clear up loose ends.
Table 1.1 details useful notational conventions used in this book.
| Notation | Unit | Example |
|---|---|---|
| italics | word-form | the word look |
| SMALL CAPITALS | lexeme | the verb lexeme LOOK (look, looks, looked, looking) |
| {...} | morpheme | the suffix {s} |
| TELETYPE | annotation | the matrix clause tag label IP-MAT |
This book's annotation approach builds on alternative annotation schemes for English. A central goal has been to consolidate strengths of existing methods in a single annotation scheme with a high degree of normalised structure. Ideas were taken from the following annotation schemes:
From the SUSANNE scheme, there is adoption of form and function information, such that the approach taken in this book can be linked most closely to the SUSANNE scheme. Moreover, a large percentage (nearly three quarters) of the Treebank Semantics Parsed Corpus (TSPC) exists as data that was converted from annotation that had been following the SUSANNE scheme.
Regarding form and function information, the SUSANNE scheme is closely related to the English grammars of Quirk et al. (1972, 1985).
The ICE Parsing Scheme similarly follows the Quirk et al. grammars. In addition, ICE is notable for its rich range of features, and care has been taken to ensure that the current annotation supports the ability for many of these features to be automatically derived.
The Penn Historical Corpora scheme, which itself draws on the bracketed approach of the Penn Treebank scheme, has informed the ‘look’ of the annotation. This includes:
However, it should be noted that, labels aside, the tag set of the current scheme is most compatible with the SUSANNE scheme, especially with regards to function marking. Moreover, word class tags closely overlap with the Lancaster word class tagging systems, especially the UCREL CLAWS5 tag set used for the British National Corpus (BNC Consortium 2005).
The annotation also contains plenty that is innovative. Notably, normalised structure is achieved with internal layers at:
Internal layers are required as support structure for CONJP layers.
Another area of innovation is the verb code integration of chapters 6, 7 and 8. The codes of chapter 6 classify catenative verbs; cf. Huddleston and Pullum (2002, p.1220). These are verbs of a verb sequence that are prior to the main verb of a clause and intermediate layers of structure labelled with a -CAT extension are included with the clause annotation to support this verb type. Additional codes of chapter 6 with very particular distributions are included from Hornby (1975). The verb codes for main verbs in chapter 7 are from the mnemonic system of the fourth edition of the Oxford Advanced Learner's Dictionary (OALD4; Cowie 1989).
The most innovative aspect of the annotation gives the TSPC its name: It can be fed to the Treebank Semantics evaluation system (Butler 2021). Treebank Semantics processes constituency tree annotations and returns logic-based meaning representations. While the annotation seldom includes indexing, results calculated with Treebank Semantics resolve both inter and intra clause dependencies, including cross sentential anaphoric dependencies. It is sometimes especially helpful to see meaning representations from Treebank Semantics as dependency graphs (e.g., from the on-line corpus interface) to make visually apparent connections that the design of the annotation captures.
As an example of sending parse structures from this book to the calculation routine of Treebank Semantics, consider (1.9) as input and its result shown as a dependency graph in (1.10).
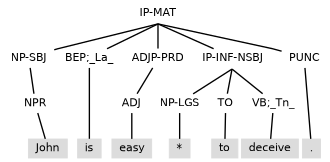
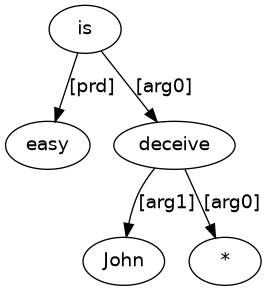
In (1.9), John is surface subject of the main clause, but, in (1.10), John is logical object ([arg1]) for deceive. Results like (1.10) unlock a fuller story of the information content the annotation captures.